INSYDER
Internet Systeme de Recherche

Members
Reiterer, Müller, Mann, Handschuh
Description
The WWW is the most important resource for external business information. With INSYDER we present a tool, which is an information assistant for finding and analysing business information from the WWW. INSYDER is a system using different agents for crawling the WWW, evaluating and visualising the results, which can be used as one important tool for the Web farming approach.
The research project INSYDER was funded by a grant from the European Union, ESPRIT project number 29232. It's located in Domain 1 - Task 1.9 (Emerging Software Technologies).
The Information Assistant INSYDER
The idea behind INSYDER is that the user has different kinds of information needs, called spheres-of-interest. Each sphere-of-interest (SOI) represents an information need of the user. The user might have a sphere-of-interest called Competitors, one Development tools, Technology and maybe one Recruitment. In each of these spheres the user can define searches, watches and portals. A typical example for a search in the competitors sphere would be to look for new competitors, while a typical watch activity would be to monitor the Web-Site of a distinctive competitor. A web portal presents interesting links to different competitors WWW-sites. The advantage of SOIs is in accordance to the user's information needs in a structured way. This will help the user to navigate between and keep different information interests at the same time, easily.
System architecture
The INSYDER system consists of several components mainly developed in Java. Only the component for the semantic analysis has been developed in C++, because it is a further development of an existing module of the project partner Arisem already written in C++.
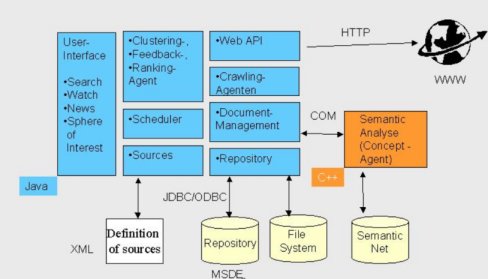
The user-interface and all visualizations have been developed in Java using the JFC (Java Foundation Classes) also called Swing. Swing allows the decoupling of the data and the different visualization views by its inherent support of the Model Viewer Control (MVC)-concept. The different agents are responsible for special retrieval tasks (e.g. crawling the Web; clustering and ranking of the search results; preparing the relevance feedback for a new crawling). The scheduler's is responsible for the Web monitoring process (called watch function). The watch-function is able to regularly check user-defined web pages for changes. The sources are the representation of starting points of a search such as commercially available search-engines, email-servers, newsgroups or directories. All sources are defined in XML documents, which enables an easy maintenance and extension of the sources in a standard-ized format. The Web-API is a set of functions and methods, which supports an easy access to the documents of the Web. The crawling agents use the Web-API for searching and crawling for Web documents, downloading them, and to put them into the document management component. The document management component is responsible for the management of all documents and their metadata. It is the central component of our architecture and implements the classes and methods for the other components, e.g. when the user interface wants to access a certain document. For every document the document management calls the semantic analysis (developed in C++) via a COM wrapper. The semantic analysis does the matching of the document and the query. Its result is a value between 0 and 100 expressing how good the document found represents the information need of the user.
Scenario of Use
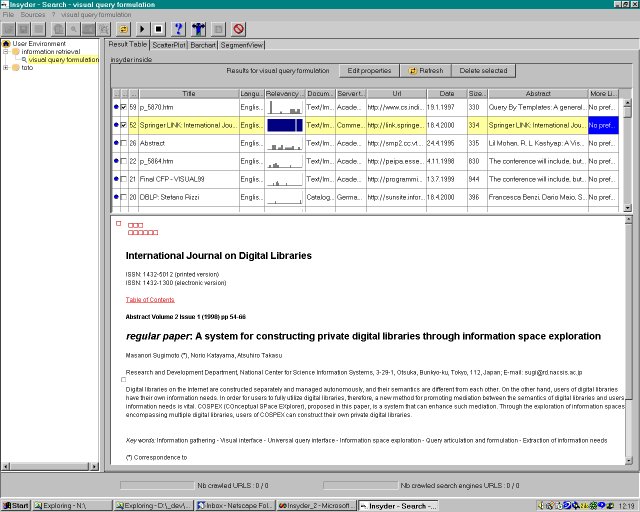
Before starting a search with INSYDER the user defines a sphere of interest. Different spheres of interest allow the user to structure his information needs and to keep a history of all searches. For this purpose we have developed a common tree-like representation of all spheres of interest (see the Figure above; the left pane shows a example of different spheres of interests summarized under a user environment, which can be exported or imported). In a further step the user formulates his in-formation need as unstructured text (often called a little bit misleading natural language) and chooses sources as starting points for the search (e.g. web sites, search engines) from a list of sources. In the following action phase the search is launched and is runing until the user stops it. During or after the search the user may want to make a review of the results having a look at the document hits. A query against the Web, even a query that is well focused, can produce so many potentially useful hits as to be overwhelming, e.g. several hundred or more. Recent work in visual information seeking systems, capitalizing on general information visualization research, has dramatically expanded the limited traditional display techniques (e.g. ranked list of hits). Therefore a variety of information visualizations techniques displaying search results have been integrated in the INSYDER system to study their efficiency, effectiveness and user satisfaction. All visualizations simply try to make the result set of the documents easier to handle. The refinement of the search is supported by the common information retrieval technique relevance feedback.
Publication list